
Show code cell source
import os
# Por precaución, cambiamos el directorio activo de Python a aquel que contenga este notebook
if "PAD-book" in os.listdir():
os.chdir(r"PAD-book/Laboratorio-Computacional-de-Analytics/S4 - Explorar, modificar y visualizar bases de datos/S4.TU3/")
Visualización intermedia#
Cuando abordamos un proyecto de analítica de datos nos enfrentamos al siguiente reto: ¿Cómo generar valor a partir de grandes volúmenes de información recolectada? Visualizar la información a través de mapas o gráficos simplifica este reto, ya que facilita la identificación de tendencias, patrones y valores atípicos. Usualmente utilizamos las visualizaciones para decidir cómo orientar nuestro análisis.
En este tutorial establecemos nociones fundamentales sobre el uso de la librería seaborn visualización de datos.
Requisitos#
Para desarrollar este tutorial necesitarás:
Utilizar estructuras de datos.
Implementar estructuras de control.
Generar visualizaciones básicas con
matplotlib.Utilizar la librería
pandas.
Objetivos#
Al final de este tutorial podrás:
1. Crear diferentes tipos de visualizaciones en seaborn.
2. Personalizar visualizaciones de manera amigable utilizando seaborn y matplotlib.pyplot.
1. Librería seaborn#
seaborn es una librería especializada en visualizaciones estadísticas para el lenguaje Python. Te recomendamos importar la libería seaborn utilizando el nombre sns (su alias más frecuentemente usado), como se muestra a continuación.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
1.1. Método displot#
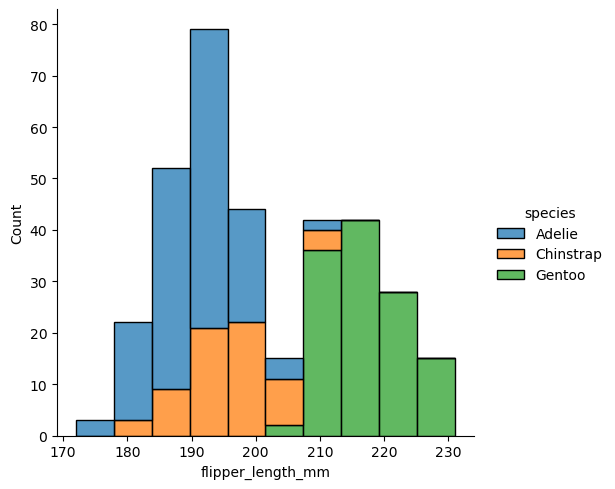
Este método nos permite crear un histograma. A continuación, crearemos un histograma a partir de información contenida en la base de datos de pingüinos de la librería seaborn.
pinguinos = sns.load_dataset("penguins") # Cargamos la base de datos de pingüinos de la librería seaborn.
sns.displot(data = pinguinos, # Utilizamos la base de datos de pingüinos.
x = "flipper_length_mm", # Establecemos la varible a la que le queremos sacar el histograma.
hue = "species", # Clasificamos los valores de acuerdo a una categoría. En este caso, especies.
multiple = "stack"); # Apilamos las barras.
1.2. Método boxplot#
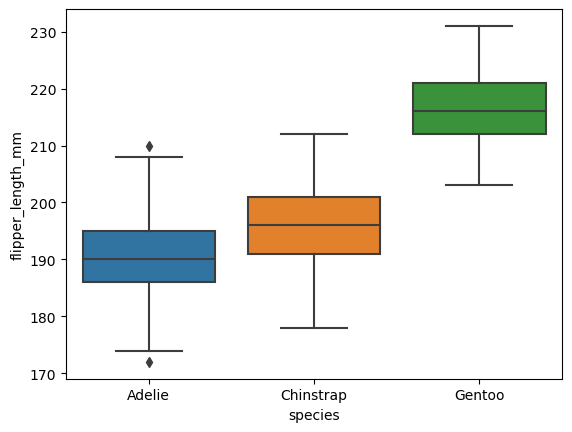
Este método nos permite crear un diagrama de caja. A continuación, crearemos un diagrama de caja a partir de información contenida en la base de datos de pingüinos de la librería seaborn.
sns.boxplot(y = "flipper_length_mm", # Establecemos la varible a la que le queremos sacar el diagrama de caja.
x = "species", # Clasificamos los valores de acuerdo a una categoría. En este caso, especies.
data = pinguinos); # Utilizamos la base de datos de pingüinos.
1.3. Método heatmap#
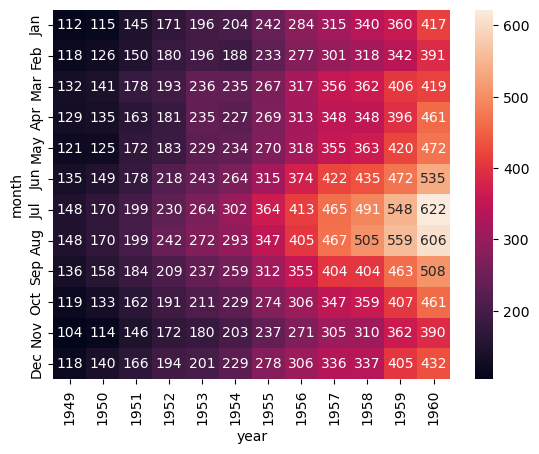
Este método nos permite crear un mapa de calor. A continuación, crearemos un mapa de calor a partir de información contenida en la base de datos de vuelos de la librería seaborn.
vuelos = sns.load_dataset("flights") # Cargamos la base de datos de vuelos de la librería seaborn.
vuelos = vuelos.pivot(index="month", columns="year", values="passengers") # Cambiamos el tamaño de la base de datos para construir un tabla con el mes, el año y los pasajeros
mapa_calor = sns.heatmap(vuelos, # Utilizamos la base de datos de vuelos.
annot = True, # Mostramos las anotaciones.
fmt = "d" # Ajustamos el formato de los números.
)
1.4. Metódo countplot#
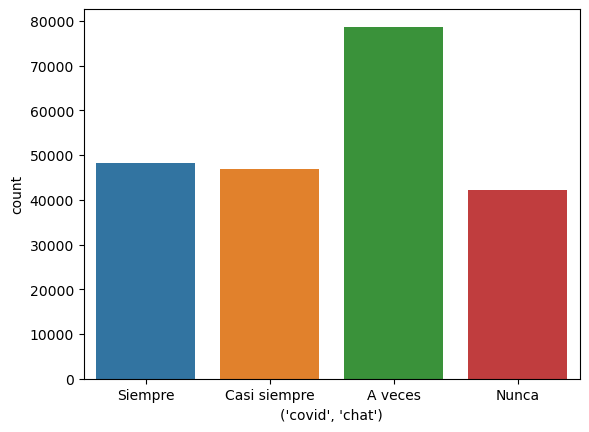
Este método nos permite crear un gráfico de barras para variables categóricas sin realizar un procesamiento previo. A continuación, crearemos un gráfico de barras para visualizar el uso del medio de comunicación de chat, por parte de un grupo de personas al momento de informarse sobre noticias generales o noticias acerca del COVID-19.
Para este ejemplo almacenamos los datos en el DataFrame df_covid_19.
df_covid_19 = pd.read_csv("./Archivos/BID-Cornell.csv", index_col = 0)
df_covid_19.columns = df_covid_19.columns.str[7:]
df_covid_19.columns = df_covid_19.columns.str.split("_", expand = True)
df_covid_19
| noti | covid | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| redessociales | chat | periodicos | tv | radio | redessociales | chat | periodicos | tv | radio | |
| id | ||||||||||
| 1000060.0 | Siempre | Siempre | Casi siempre | A veces | Nunca | Siempre | Siempre | Siempre | A veces | Nunca |
| 1000734.0 | Casi siempre | A veces | A veces | Casi siempre | Casi siempre | Casi siempre | Casi siempre | A veces | Casi siempre | Casi siempre |
| 1000120.0 | Nunca | A veces | A veces | Siempre | Siempre | Nunca | A veces | A veces | Siempre | Siempre |
| 1000235.0 | Siempre | Siempre | A veces | A veces | A veces | Siempre | Siempre | Nunca | A veces | Nunca |
| 1000828.0 | Casi siempre | A veces | A veces | A veces | A veces | Casi siempre | Casi siempre | A veces | A veces | Nunca |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 17001614.0 | A veces | A veces | Casi siempre | Siempre | Casi siempre | Nunca | A veces | Casi siempre | Siempre | Casi siempre |
| 17017448.0 | Siempre | Siempre | A veces | A veces | Nunca | Siempre | Siempre | A veces | A veces | Nunca |
| 17013032.0 | Siempre | Siempre | Siempre | Siempre | Siempre | Siempre | Casi siempre | Siempre | Siempre | Siempre |
| 17014760.0 | Siempre | Siempre | Siempre | Casi siempre | Casi siempre | Siempre | Siempre | Siempre | Casi siempre | Casi siempre |
| 17003990.0 | Casi siempre | Nunca | Nunca | Casi siempre | Casi siempre | Casi siempre | Nunca | A veces | Casi siempre | Casi siempre |
216092 rows × 10 columns
data = df_covid_19.loc[:, pd.IndexSlice[:, 'chat']] # Filtramos los datos con el objetivo de analizar el uso del medio de comunicación de chat.
display(data)
# Declaramos el gráfico de barras utilizando el método countplot.
ax = sns.countplot(x = pd.IndexSlice['covid', 'chat'], # Ubicamos las categorías de la frencuencia del uso de este medio de comunicación en el eje x.
data = data # Utilizamos los datos filtrados previamente.
)
| noti | covid | |
|---|---|---|
| chat | chat | |
| id | ||
| 1000060.0 | Siempre | Siempre |
| 1000734.0 | A veces | Casi siempre |
| 1000120.0 | A veces | A veces |
| 1000235.0 | Siempre | Siempre |
| 1000828.0 | A veces | Casi siempre |
| ... | ... | ... |
| 17001614.0 | A veces | A veces |
| 17017448.0 | Siempre | Siempre |
| 17013032.0 | Siempre | Casi siempre |
| 17014760.0 | Siempre | Siempre |
| 17003990.0 | Nunca | Nunca |
216092 rows × 2 columns
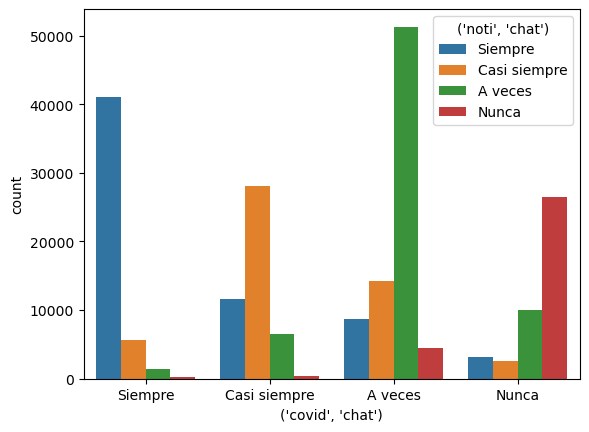
Ahora, utilizaremos el parámetro hue para añadir el uso del medio de comunicación de las noticias a nuestra visualización. Además, utilizaremos el parámetro hue_order para establecer el orden en el que queremos que aparezcan las categorías en nuestra visualización.
ax = sns.countplot(x = pd.IndexSlice['covid', 'chat'], # Añadimos otra categoría a la visualización: el uso del medio de comunicación de las noticias.
hue = pd.IndexSlice['noti', 'chat'], # Ubicamos las categorías de la frencuencia del uso de este medio de comunicación en el eje x.
hue_order = ['Siempre', 'Casi siempre', 'A veces', 'Nunca'], # Establecemos un orden para las categorías.
data = data # Utilizamos los datos filtrados previamente.
)
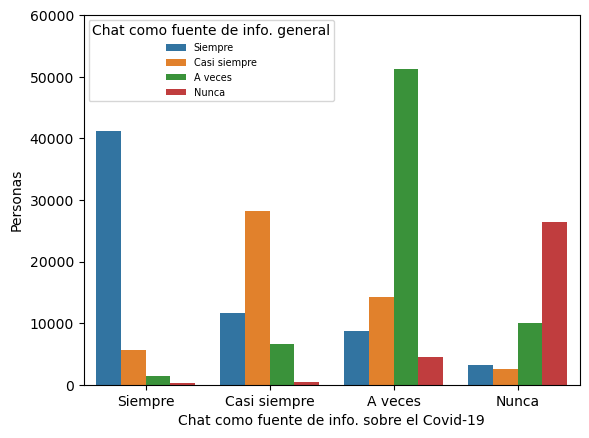
Por último, editamos el gráfico. Para esto, utilizamos los métodos vistos anteriormente para los objetos de tipo axes y el módulo pyplot de matplotlib.
# Declaramos el gráfico de barras utilizando el método countplot.
ax = sns.countplot(x = pd.IndexSlice['covid', 'chat'],
hue = pd.IndexSlice['noti', 'chat'],
hue_order = ['Siempre', 'Casi siempre', 'A veces', 'Nunca'],
data = data
)
ax.legend_.remove() # Eliminamos la leyenda del gráfico.
ax.set(xlabel = 'Chat como fuente de info. sobre el Covid-19', # Añadimos una etiqueta al eje x.
ylabel = 'Personas' # Añadimos una etiqueta al eje y.
)
ax.set_ybound(upper = 60000) # Declaramos el límite superior en 60000.
# Modificamos la leyenda de la visualización.
plt.legend(title = 'Chat como fuente de info. general', # Añadimos título a la visualización.
loc = 'upper left', # Ubicamos la leyenda en la parte superior izquierda.
labels = ['Siempre', 'Casi siempre', 'A veces', 'Nunca'], # Añadimos etiquetas de datos.
prop = {'size': 7} # Definimos el tamaño de la leyenda.
)
# Mostramos la visualización.
plt.show(ax)
Referencias#
Seaborn (2020). Seaborn: statistical data visualization. Recuperado el 11 de febrero de 2020 de: https://seaborn.pydata.org/index.html
Créditos#
Autores: Juan David Reyes Jaimes, Jorge Esteban Camargo Forero, Alejandro Mantilla Redondo, Maria Camila Diaz, Diego Alejandro Cely Gómez
Fecha última actualización: 12/07/2022